
学习笔记:Linux(尚硅谷)
介绍
- 本文主要记录在学习尚硅谷的 Linux 课程时的一些笔记
- 尚硅谷前端学科全套课程请点击这里进行下载,提取码:afyt
一、基础部分
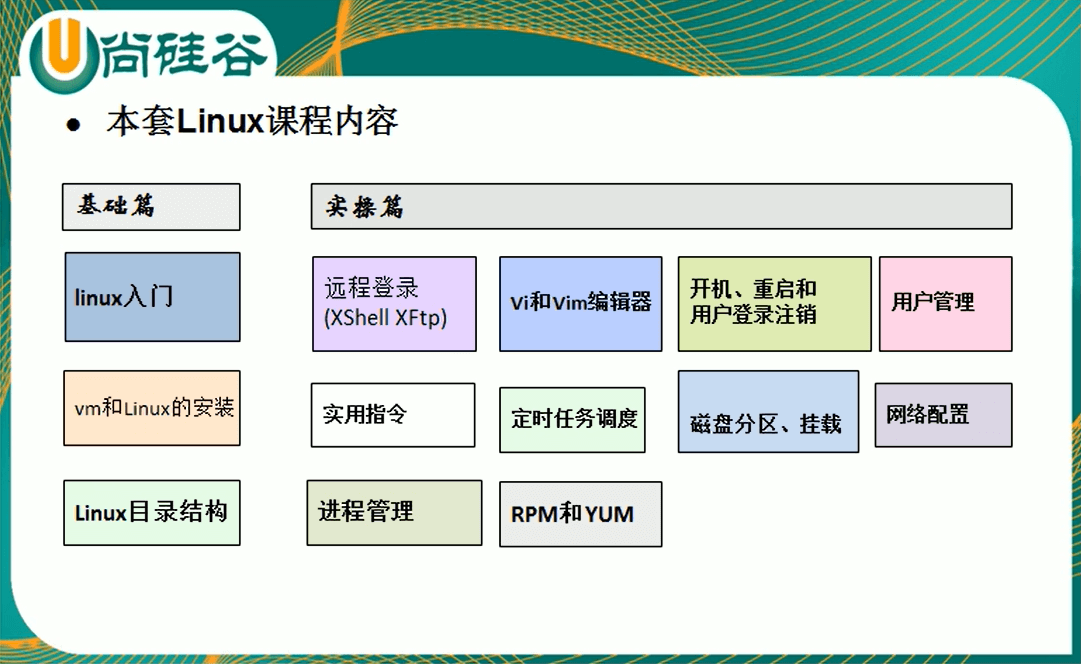
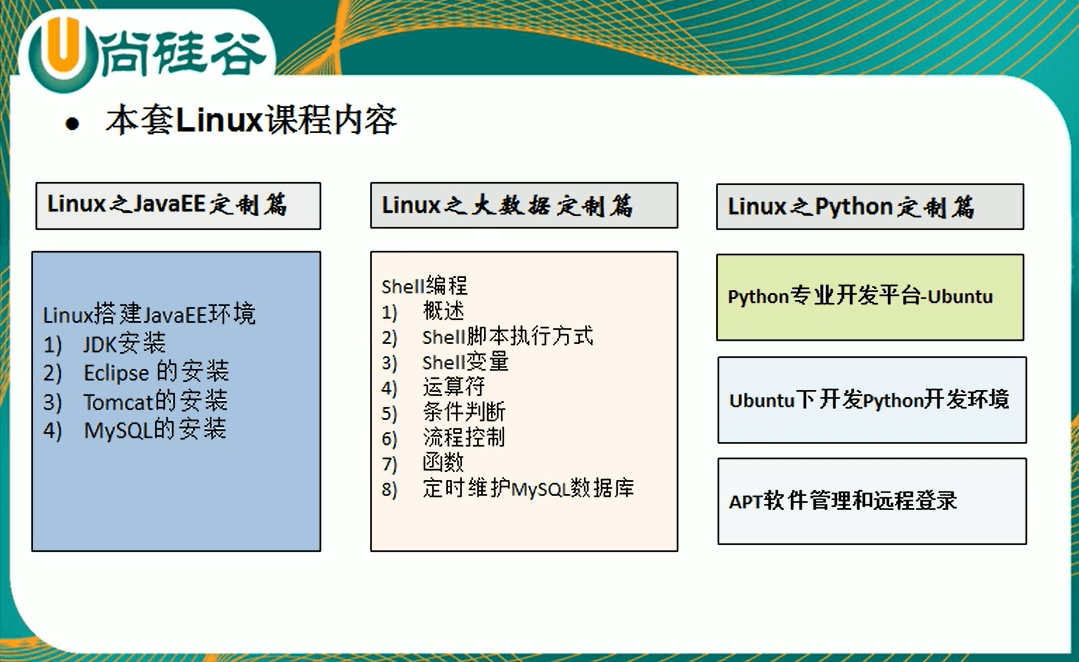
1.学习内容
基础 & 实操篇
定制篇
2.学习方向
Linux 运维工程师:服务器的规划、调试优化、日常监控、故障处理、数据备份、日志分析
Linux 嵌入式工程师:掌握Linux下各种驱动程序开发、在嵌入式系统中进行程序开发
Linux 下开发项目:JavaEE、大数据、Python、PHP、C、C++
3.进阶之路
主要有6个阶段:

4.VM虚拟机相关知识
桥接模式:Linux系统可以与其他系统通信,但会占用真实网络中的ip地址,而一个网段的ip地址是有限的,所以一般不使用该模式
NAT 模式:该模式会在真实主机上新建一个ip地址,然后在这个ip地址下划分子网给虚拟机中的Linux,这样子外部主机无法访问到Linux,但Linux可以使用主机真实ip代理访问其他主机
装Linux系统时,自定义分区为:标准分区/boot :200M左右交换分区swap :该分区没有挂载点,一般为物理内存的1.5-2倍之间根分区/ :剩余所有空间
共享文件夹会默认放在 centos 下的
/mnt/hgfs
5.目录结构
在linux中,一切都是文件
/ :根目录
/bin :存放命令
/boot :存放启动linux时的核心文件
/dev :管理设备
/etc :存放配置文件
/home :普通用户对应的文件
/lib :存放库文件
/lost+found :系统非法关机后存放文件
/media :外接设备
/mnt :为了让用户临时挂载别的文件系统
/opt :放置需要安装的软件
/proc :有关内核的文件
/sbin :存放系统管理员使用的系统管理程序
/selinux :安全目录,类似于windows下的360
/srv :存放服务启动后需要提取的数据
/sys :linux2.6内核以后会生成该文件夹
/tmp :存放临时文件
/usr :用户安装的文件和应用程序
/var :存放日志
6.远程登录
使用 Xshell 和 Xftp 远程登录 Linux 系统
实现远程登录时,需要 Linux 系统开启一个 sshd 的服务,该服务会监听22号端口。该服务一般是默认打开的,检查是否打开需要在终端输入
setup-> 系统服务 -> sshd -> *号代表已经打开注意:端口开的越多,安全性就越弱
7.用户管理
Linux的用户至少要属于一个组
(1).添加用户
useradd [选项] 用户名:会自动创建和用户同名的家目录useradd -d 指定目录 用户名:创建用户并指定家目录useradd -g 用户组 用户名:创建用户并指定用户组(该组存在才可以指定)
(2).添加密码
passwd 用户名:为该用户添加密码
(3).删除用户
userdel 用户名:删除用户但保留家目录userdel -r 用户名:删除用户及家目录
(4).查询用户
id
(5).切换用户
su - 用户名高权限用户切换到低权限用户时,不需要密码,但权限会降低,使用
exit可以退出当前用户退回到原来用户
(6).相关文件
/etc/passwd:用户信息文件(用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell)/etc/shadow:用户密码文件(登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标志)/etc/group:用户组配置文件(组名:口令:组标识号:组内用户列表)
8.用户组
(1).增加组
groupadd 组名
(2).删除组
groudel 组名
(3).修改组
usermod -g 用户组 用户名
二、指令部分
1.帮助类
(1).man
作用:manual(手册),包含了linux中全部命令手册
man 命令:退出按q即可
(2).help
语法:
help 指令
2.压缩类
(1).gzip/gunzip
作用:前者为压缩文件,后者为解压缩文件
gzip 文件名:会直接删除源文件
(2).zip/unzip
作用:前者为压缩文件,后者为解压缩文件
zip 选项 文件名 存放路径:选项如下:
-r:递归压缩unzip 选项 存放目录 压缩文件名:选项如下:
-d:指定解压后文件的存放目录
(3).tar
作用:打包指令,文件后缀为
tar.gztar 选项 打包后的文件名 打包的内容,选项如下:
-c:产生.tar打包文件
-v:显示详细信息
-f:指定压缩后的文件名
-z:打包同时压缩
-x:解包.tar文件zcvf为压缩,zxvf为解压
注意:指定解压到某个目录,需要在目录前面使用 -C 才可以成功
3.用户类
(1).id
作用:查看一个用户的基本信息(用户,用户组,附加组id)
id:默认显示当前执行命令的用户的基本信息id 用户名:显示指定用户的基本信息
!如何验证信息是否正确
验证用户信息通过文件
/etc/passwd验证用户组信息通过文件
/etc/group
(2).whoami
作用:显示当前登陆的用户名,一般用于 shell 脚本,来获取当前登陆的用户名方便记录日志
whoami
4.系统类
(1).logout
作用:注销当前用户,减少服务器开销
logout注意:该命令在图形化界面无效,只在命令行模式下有效
(2).reboot
作用:重新启动计算机
rebootreboot -w:模拟重启但是不重启(只写关机与开机的日志信息)shutdown -r now:立即重启
(3).shutdown
作用:关机(慎用)
shutdown -h now:立即关机shutdown -h now "提示文字":立即关机并带有提示性文字shutdown -h 1:1分钟后关机shutdown -h 12:00:12:00关机shutdown -h 12:00 "提示文字":12:00关机并带有提示性文字注意:在centos 7之前,取消关机计划需要使用
ctrl+c命令;在centos7 及之后可以使用shutdown -c命令
(4).关机
shutdown -h now:正常关机halt:关闭内存poweroff:关闭电源init 0:以后版本不一定能用
(5).root
sudo passwd root:设置密码su:切换root用户
(6).clear
作用:用来清除终端中已经存在的命令和结果,快捷键为ctrl+L
clear
(7).hostname
作用:操作服务器的主机名(读取,设置),这里设置的主机名是临时的,所以一般不使用该命令来设置主机名,只用作读取
hostname:输出完整的主机名hostname -f:输出当前主机名的FQDN(全限定域名)
(8).uptime
作用:输出计算机的持续在线时间
uptime
(9).uname
作用:获取操作系统的相关信息
uname:获取操作系统的类型uname -a:获取全部的系统信息(类型、全部的主机名、内核版本、发布时间、开源计划)
(10).sync
作用:把内存的数据同步到磁盘
sync注意:当我们关机或者重启时,都应该执行以下这个命令,防止数据丢失
(11).free
作用:查看内存使用情况,主要看第二行内容,swap 用于临时内存
free:以默认单位进行查看free -m:以 mb 为单位进行查看
5.运行级别类
开机的流程:开机 - BIOS - /boot - init进程1 - 运行级别 - 运行级对应的服务
系统的运行级别配置文件在
/etc/inittab目录下运行级别有如下:
0:关机
1:单用户
2:多用户状态没有网络服务
3:多用户状态有网络服务
4:系统未使用保留给用户
5:图形界面
6:系统重启常用运行级别是3和5
切换到指定运行级别的指令:
init [012356]查看或修改默认级别:
vi /etc/init.d
!引申:面试题之怎样找回root密码
在开机进入引导时,按下回车键,进入一个代码界面,按e键进入后选择第二行(编辑内核)然后再按e键
输入1按回车键再输入b进入单用户模式
使用
passwd指令进行修改密码
6.文件目录类
(0).vi & vim
作用:文本编辑器
三种常见模式:正常模式:使用命令进入后的界面插入模式(编辑模式):可以输入内容命令行模式:可以输入相关的命令
vim 文件的路径:进入编辑器
!常用命令:
i、I、o、O、a、A、r、R:进入编辑模式Esc:退出编辑模式或命令模式:或/:进入命令行模式q:没有修改时直接退出wq:保存并退出!q:强制退出
!快捷键
p:粘贴u:撤销yy:拷贝当前行5yy:拷贝当前行向下的5行dd:删除当前行5dd:删除当前行向下的5行G:跳转到文档的最末行
gg:跳转到文档的首行/关键字:命令行下输入按回车可以查找,输入n就是查找下一个:set nu:命令行下输入可以设置文件的行号set nonu:取消文件的行号跳转到某一行:先设置行号,然后在正常模式下输入需要跳转的行号,然后按
shift+g其余快捷键可以查看菜鸟教程中的内容
!注释
单行注释
1 | #这个是单行注释 |
多行注释
1 | :<<! |
(1).ls
作用:列出所有文件和文件夹
lsls 路径ls 选项 路径
ls -l 路径:以详细列表显示所有文件
ls -la 路径:以详细列表显示所有文件和隐藏文件
ls -lh 路径:以合适的大小显示所有文件
(2).pwd
作用:打印当前工作目录
pwd
(3).cd
作用:改变或切换当前工作目录
cd 路径cd ~:切换到当前用户的家目录cd ..:切换到当前用户的上一级目录
(4).mkdir
作用:创建目录
mkdir [选项] 路径mkdir -p 路径:进行多层目录的创建mkdir 路径1 路径2 路径3:同时创建多个目录
(5).touch
作用:创建文件
touch 路径:同上touch 路径1 路径2 路径3:同上
(6).cp
作用:复制文件或文件夹
cp 复制前的路径 复制后的路径:复制文件cp 复制前的路径 复制后的路径 -r:复制文件夹包含文件,-r表示递归\cp -r 路径 路径:当目标目录下有相同文件,可以强制覆盖
(7).mv
作用:移动、剪切文档到新的位置
mv 旧路径/文件名 新路径/原文件名:移动但不重命名mv 旧路径/文件名 新路径/新文件名:移动并重命名mv 旧路径/文件夹 新路径/原文件夹:移动但不重命名,移动文件夹无需写-rmv 旧路径/文件夹 新路径/新文件夹:移动并重命名,移动文件夹无需写-r
(8).rm
作用:删除文档
rm 选项 需要移除的路径rm -f 路径:强制删除,不提示rm -rf 路径:强制递归删除非空目录,不提示rm -f linux*:删除以linux开头的文件,星号为通配符rm 路径1 路径2 路径3
(9).cat
作用:打开文件(只能浏览)或者合并文件
cat 文件的路径:直接打开一个文件,为了浏览方便,一般会在后面使用管道连接 ——| morecat 待合并的文件路径1 待合并的路径2 > 合并之后的文件路径:合并文件
(10).more
作用:以全屏的方式按页显示文本文件的内容
more 要查看的文件enter:一行一行的翻空格:一页一页的翻
Ctrl+b:上一页
Ctrl+f:下一页
q:退出
(11).less
作用:分屏查看文件内容,以较少的内容输出
less 要查看的文件enter:一行一行的翻空格:一页一页的翻
Ctrl+b:上一页
Ctrl+f:下一页
q:退出
(12).> & >>
作用:可以重定向文件或者新建文件
>:输出重定向,覆盖输出,会覆盖原先文件内容>>:追加,追加输出,不会覆盖,会在文件末尾继续添加基本语法:
ls -l > a.txt:将前面的输出内容覆盖写入到a.txt文件cat /etc/profile >> a.txt:将固定文件内容追加输出到a.txtecho "Hello,world!" > a.txt:将固定语句覆盖写入到a.txt
(13).echo
作用:输出内容到控制台
echo $PATH:输出环境变量到控制台echo "Hello"
(14).head
作用:查看一个文件的前n行
head 需要查看文件的路径:默认显示前10行head -n 需要查看文件的路径:查看一个文件的前n行
(15).tail
作用:查看文件末n行或者动态变化
tail 需要查看文件的路径:默认显示末10行tail -n 需要查看文件的路径:查看一个文件的末n行tail -f 文件的路径:查看文件动态变化,常用!
(16).ln
作用:软链接指令,主要存放了链接其他文件的路径
ln -s 原文件或目录 软链接名字rm -rf 软链接名字:删除软链接,后面加斜杠会删除原文件内容!
(17).history
作用:查看已经执行过的历史命令,也可以执行历史命令
history!数字:直接执行历史编号的命令
(18).wc
作用:统计文件内容信息(行数、单词数、字节数)
wc -lwc 需要统计的文件路径
(19).du
作用:查看目录的真实大小
du -sh 路径:-s表示只显示汇总的大小,-h表示以较高可读性的形式进行显示
7.时间日期类
(1).date
作用:进行时间日期等相应的读取和设置
date:显示当前时间date +%F与date "+%Y-%m-%d":显示年月日,如:2019-01-02date "+%F %T"与date "+%Y-%m-%d %H:%M:%S":显示年月日时分秒,如:2018-12-28 23:40:16(引号表示让年月日与时分秒成为不可分割的整体)data -d "-1 day" "+%Y-%m-%d %H:%M:%S":获取之前或者之后(+1)的某个时间(年月日)date -s 字符串时间:设置系统当前时间,!重点!
(2).cal
作用:进行日历相应的操作
cal -1:直接输出当前月份的日历cal -3:输出上一个月,当月和下一个月的日历cal -y 2018:输出一年的日历
8.搜索查找类
(1).find
作用:用于查找文件,从指定目录向下递归地遍历查找(参数有55个)
find 路径范围 选项 选项的值,选项有:
-name :按照文档名称进行搜索(支持模糊搜索)
-user :按照文档用户名进行搜索
-size :按照文档大小进行搜索,后面跟+20M(大于20M)
-type :按照文档的类型进行搜索(-为文件,这里使用f来替换;d表示文件夹)注意:尽量不要在根目录下进行查找
(2).locate
作用:可以快速定位文件路径,其无需遍历整个文件系统,查询速度比较快
由于 locate 指令基于数据库进行查询,所以第一次运行前,必须使用 updatedb 指令创建其的数据库
locate 文件名
(3).grep 与 |
作用:管道一般可以用于 “过滤,特殊,扩展处理”
注意:不能单独使用,必须配合其他命令使用,主要起辅助作用
grep 选项 查找内容 源文件:选项如下:
-n:显示匹配行及行号
-i:忽略字母大小写ls / | grep y:过滤功能ls / l wc -l:统计某个目录下的文档总个数
9.工作常用类
统计/home文件夹下文件的个数:
ls -l /home | grep "^-" | wc -l统计/home文件夹下目录的个数:
ls -l /home | grep "^d" | wc -l统计/home文件夹下文件的个数,包括子文件里的:
ls -lR /home | grep "^-" | wc -l统计文件夹下目录的个数,包括子文件夹里的:
ls -lR /home | grep "^d" | wc -l以树状显示目录结构:
tree(如果没有该命令可以使用yum进行安装)
三、实操部分
1.组管理和权限管理
(1).查看文件所有者/所在组
ls -ahl
(2).修改文件所有者
chown 用户名 文件名:改变文件的所有者chown newowner:newgroup 文件名:改变文件的所有者和所有组chown -R tom kkk/:将 kkk 目录下的所有的文件(子目录及其下边的文件),递归的将所有者改成tom
(3).修改文件所在组
chgrp 组名 文件名
(4).修改用户所在组
usermod -g 组名 用户名usermod -d 目录名 用户名:改变该用户登录的初始目录
(5).权限介绍
使用
ls -l可以查看权限文件的类型:
-为普通文件、d为目录、l为软链接、c为字符设备、b为块文件文件所有者(所在组、其他组)权限:
r为读权限(4)、w为写权限(2)、x为执行权限(1) 、-为没有权限
(6).修改权限
u:所有者;g:所有组;o:其他人;a:所有人
chmod u=rwx,g=rw,o=x 文件目录名或chmod 751 文件目录名chmod 0+w 文件目录名chmod a-x 文件目录名
2.crond任务调度
(1).基础
作用:crontab 进行定时任务的设置
crontab 选项,选项如下:
-e:编辑 crontab 定时任务
-l:查询 crontab 任务
-r:删除当前用户所有的 crontab 任务service cround restart:重启任务调度简单的任务,可以不用写脚本,直接在 crontab 中直接编写即可;复杂任务,需要使用 shell 脚本编写
(2).步骤
crontab -e
*/1 * * * * ls -l /etc >> /tmp/to.txt
当程序退出后就生效
(3).占位符说明
如下图:
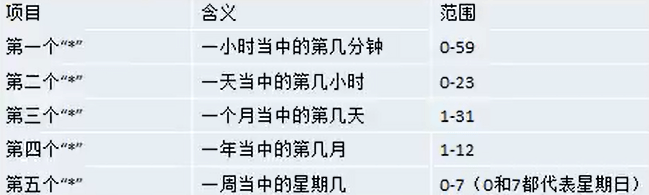
(4).特殊符号说明
如下图:

(5).特定时间执行任务案例
如下图:

3.磁盘管理
(1).分区
mbr分区:最多支持四个主分区系统只能装在主分区扩展分区要占一个主分区
mbr最大只支持2TB,但拥有最好的兼容性gpt分区:支持无限多个主分区最大支持18EB的大容量
win7 64位以后支持gptLinux中无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,一个独立且唯一的文件结构,Linux中每个分区都是用来组成整个文件系统的一部分
Linux采用了一种“载入”的处理方法,它的整个文件系统中包含了一整套的文件和目录,且将一个分区和一个目录联系起来
mount:挂载
umount:卸载使用
lsblk(老师不离开首字母)命令查看系统的分区和挂载的情况(加-f选项也可以)
(2).硬盘
Linux硬盘分为 IDE 硬盘和 SCSI 硬盘,目前基本上是 SCSI 硬盘
对于 IDE 硬盘,驱动器标识符为
hdx~
hd:指该硬盘为 IDE 硬盘
x:为盘号(a为基本盘,b为基本从属盘,c为辅助主盘,d为辅助从属盘)
~:为分区,1-4表示为主分区或扩展分区,从5开始表示逻辑分区对于 SCSI 硬盘,驱动器标识符为
sdx~
sd:指该硬盘为 SCSI 硬盘
x:为盘号(a为基本盘,b为基本从属盘,c为辅助主盘,d为辅助从属盘)
~:为分区,1-4表示为主分区或扩展分区,从5开始表示逻辑分区
(3).挂载案例——增加一块硬盘
1).虚拟机添加硬盘
在虚拟机菜单中,选择设置,然后添加硬盘,下一步,修改磁盘大小,重启系统
2).分区
使用分区命令
fdisk /dev/sdb,分区时有如下命令:
m:显示命令列表
p:显示磁盘分区,同fdisk -l
n:新增分区
d:删除分区
w:写入并退出开始分区后输入n来新增分区,然后选择p,分区类型为主分区即1。两次回车默认剩余全部空间。最后输入w写入分区并退出,若不保存退出输入q
3).格式化
使用
mkfs -t ext4 /dev/sdb1命令来执行,其中ext4为分区类型注意:这里的分区类型可能需要视不同版本或不同系统而定
4).挂载
挂载可以使一个分区与一个目录联系起来
命令为:
mount 设备名称 挂载目录。例如:mount /dev/sdb1 /home/newdisk卸载命令为:
umount 设备名称/挂载目录注意:这部分的挂载在系统重启以后会失效,所以需要使用下一步永久挂载
5).设置可以自动挂载
修改
/etc/fstab文件可实现挂载将最上边有UUID部分的复制一行以后进行修改,第一部分修改为设备名称,第二部分为挂载目录,第三部分为分区类型,第四部分为默认,第五部分按00即可
添加完成后,执行
mount -a即刻生效
(4).df
df:直接查看磁盘空间df -h:查询系统整体磁盘使用情况du -ach --max-depth=1 /目录:查询指定目录的磁盘占用情况,默认为当前目录
-s:指定目录占用大小汇总
-h:带计量单位
-a:含文件
-c:列出明细的同时,增加汇总值
–max-depth=1:子目录深度
4.网络配置与管理
(1).查看网络IP和网关
查看虚拟网络编辑器:虚拟机编辑菜单-虚拟网络编辑器-VMnet8
在这里还可以修改虚拟机的ip地址
查看网关:虚拟机编辑菜单-虚拟网络编辑器-VMnet8-NAT设置
(2).自动获取IP
Linux系统中:系统-首选项-网络连接-点击相应网卡-编辑-自动连接
然后重启一下即可
缺点:每次自动获取的IP地址可能不一样,服务器上不适用
(3).修改配置文件指定IP
编辑
/etc/sysconfig/network-scripts/ifcfg-eth0文件,对于最后是网关文件可能不一定是0设置为静态获取ip,并配置IP、网关、DNS,如下图:
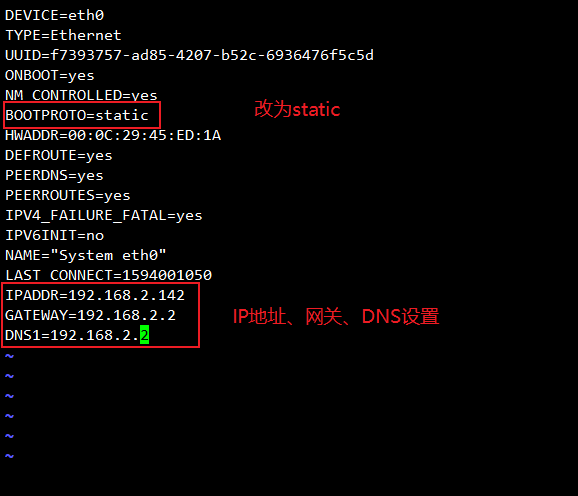
重启网络服务:
service network restart
(4).netstat
作用:查看网络的连接状态
netstat -tnlp:
-t表示只列出tcp协议的连接
-n表示将字母组合转化成ip地址,将协议转换成端口号
-l表示过滤出"state"列中其值为 LISTEN 的连接
-p表示显示发起连接的pid和进程名称
(5).ifconfig
作用:操作网卡的相关的指令
ifconfig;获取网卡信息
5.进程管理
(1).基础
在 Linux 中,每个执行的程序都称为一个进程,且分配一个 ID 号
一个进程 ——> 一个父进程一个父进程 ——> 多个子进程
进程分为前台进程和后台进程(又称守护进程)
(2).ps
作用:查看服务器的进程信息
注意:使用该命令至少会出现一个进程,因为自身命令也算一次进程
!命令1:
ps -aux,选项如下:
-a:显示当前终端的所有进程信息
-u:以用户的格式显示进程信息
-x:显示后台进程运行的参数为了查看方便,这里建议与 more 指令一起使用,即
ps -aux | more关于每一列的含义,如下图:
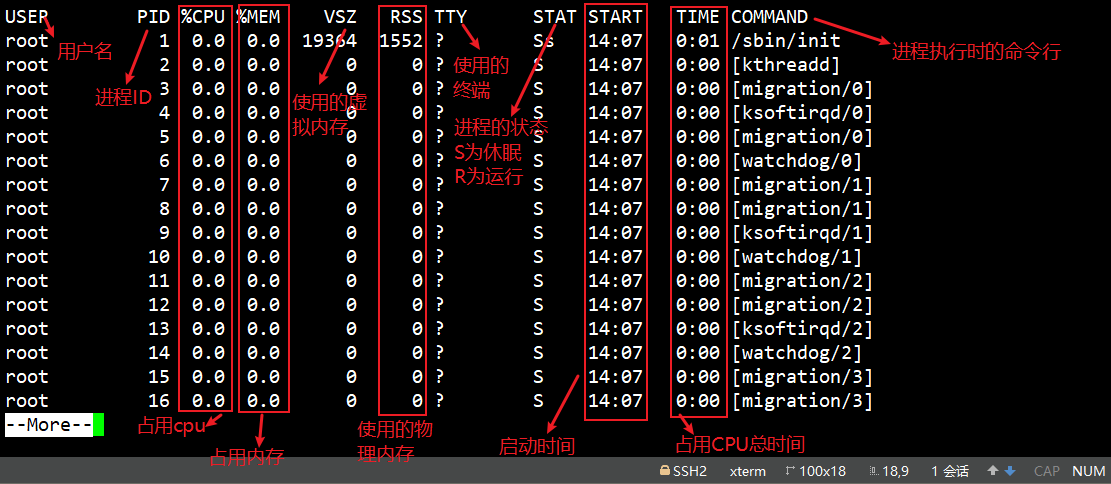
!命令2:
ps -ef:主要用来查看父进程
-e:列出全部的进程
-f:显示全部的列(显示全字段)进程的主要参数如下图:
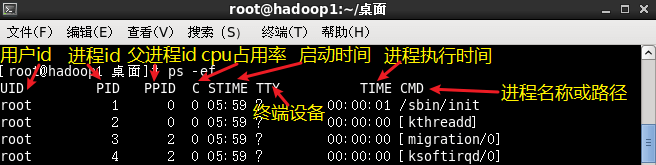
注意:如果一个程序的父级进程找不到,则为僵尸进程(STAT为Z),需要进行处理
!进阶(100%使用)
基础方法会查看所有的进程,然后在实际中并不需要,所以可以用管道进行过滤
ps -ef | grep 进程名字与ps -aux | grep 进程名字
(3).kill
作用:用于杀死进程(当遇到僵尸进程或者需要关闭进程的时候)
kill 选项 进程id(pid):通过进程号杀死进程常用选项:-9表示强迫进程立即停止killall 进程名称:通过进程名称杀死进程,也支持通配符,在系统因负载过大而变得很慢时很有用
!案例演示:
踢出非法登录用户:
1 | ps -aux | grep sshd //查看非法登录用户的PID |
终止远程服务 sshd,在适当的时候再次重启 sshd 服务
1 | ps -aux | grep sshd |
终止多个 gedit 编辑器
1 | killall gedit |
强制杀掉一个终端,终端对应一个 bash
1 | ps -aux | gerp bash |
(4).pstree
作用:用树状来查看进程信息
pstree 选项,常用选项如下:
-p:显示进程的PID
-u:显示进程的所属用户
(5).Service
服务本质就是进程,但是是运行在后台的,通常都会监听某个端口,等待其他程序的请求,因此又称为守护进程
作用:控制一些软件的服务启动/停止/重启/重载/状态
service 服务名 start/stop/restart/reload/status注意:在 Centos7.0 以后不再使用 service 命令,而是使用 systemctl 命令
注意:使用该命令执行以后会立即生效,但重启失效
!案例分析
查看当前防火墙状况
1 | service iptables status |
!检测端口号是否被监听
在 Windows 端使用 Telnet客户端来检测
需要先在 程序和功能-启用或关闭Windows功能-Telnet 打钩
然后在 cmd 命令行中输入以下命令:
1 | telnet ip地址 端口号 |
!查看服务名
使用 setup 命令->系统服务
ls -l /etc/init.d/查看
(6).chkconfig
作用:可以给各个运行级别设置自启动/关闭
chkconfig --list:查看全部服务chkconfig --list | grep xxx或chkconfig 服务名 --list:查看具体某一个服务chkconfig --level 运行级别 服务名 on/off:设置某个服务的运行级别自启动
(7).top(动态监控进程)
作用:查看服务器的进程占的资源,且会自动更新
top:进入命令,动态显示u:回车后输入用户名查看该用户下的进程k:回车后输入进程ID号可以终止指定的进程M:将结果按照内存(MER)从高到低进行排列N:将结果按照PID排序P:将结果按照CPU从高到低进行排列1:当服务器拥有多个cpu的时候,使用1来切换是否展示显示cpu的详细信息q:退出命令详细信息如下图:
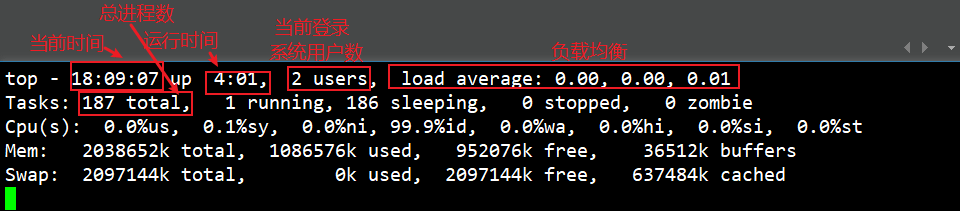
进程所占资源如下图:
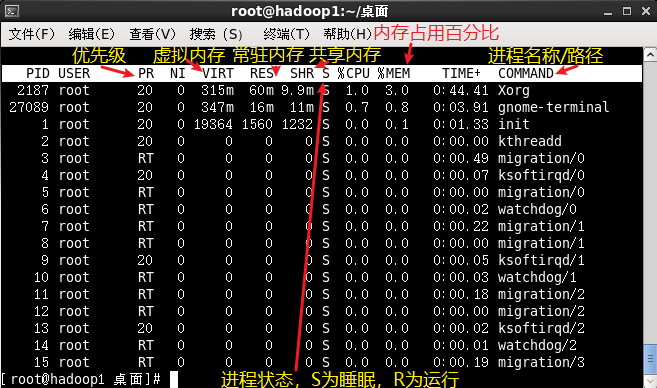
top 选项,具体选项如下:
-d 10:指定10秒刷新一次
-i:不显示任何闲置或者僵死进程
-p:通过指定监控进程ID来仅仅监控某个进程的状态计算一个进程实际使用的内存 = 常驻内存 - 共享内存
(8).netstat(监控网络状态)
作用:查看系统网络情况
netstat -anp,选项如下:
-an:按一定顺序排列输出
-p:显示哪个进程在调用
6.RPM包管理
rpm 选项选项如下:
-qa:查询所安装的所有软件包
-q 软件包名:查询软件包是否安装
-qa | grep 软件包名:查询软件包是否安装
-qi 软件包名:查询软件包信息
-ql 软件包名:查询软件包中的文件
-qf 文件全路径名:查询文件所属的软件包rpm -e 软件包名:删除该软件包rpm -e -nodeps 软件包名:强制删除某软件包rpm -ivh RPM包全路径名称:安装某软件包
-i:安装
-v:提示
-h:进度条安装时候需要先挂载安装系统的ISO文件,然后去
/media/Packages下找到包,将其复制到/opt/中,再进行安装
7.yum包管理
yum 是一个 Shell 前端软件包管理器,基于 RPM包管理,可以从指定的服务器自动下载 RPM包并进行安装,还可以自动处理依赖关系
yum list | grep xx:查询软件列表中是否有这个软件yum install xxx:下载并安装
四、JavaEE定制部分
1.准备文件
在 Linux 上开发 Java 程序需要安装以下4个软件:jdk、tomcat、eclipse、MySQL
下载好以后使用 Xftp 上传到服务器的
/opt/目录下
2.安装 jdk
将 jdk 安装包解压到
/opt/目录下配置环境变量
vim /etc/profile,在最后一行添加如下内容
1 | JAVA_HOME=/opt/jdk1.7.0_79 //解压后的文件夹名 |
使用
source /etc/profile命令来使环境变量生效,也可以直接注销重新登录
3.安装 Tomcat
将 Tomcat 安装包解压到
/opt/目录下切入到解压后文件夹的
/bin目录执行
./startup.sh命令来运行 Tomcat在服务器的浏览器中输入
http://localhost:8080来检测是否成功启用 Tomcat但是本地电脑却无法访问是因为防火墙没有让8080端口通过,所以可以修改
/etc/sysconfig/iptables文件来让8080端口通过,将其中含有22端口的一行复制并粘贴修改为8080,然后使用service iptables restart来重启防火墙就可以了
4.安装 Eclipse
将 Eclipse 安装包解压到
/opt/目录下进入解压后的文件夹,使用
./eclipse命令启动 eclipse,注意配置jre与Tomcat
5.安装 MySQL
(1).卸载旧版本
使用
rpm -qa | grep mysql命令检查是否安装有 MySQL Server如果有的话通过
rpm -e mysql-libs或rpm -e --nodeps mysql-libs命令来卸载掉
(2).安装编译代码需要的包
使用
yum -y install make gcc-c++ cmake bison-devel ncurses-devel命令来安装编译代码需要的包将 MySQL 安装包解压到
/opt/目录下进入解压后的文件夹后输入以下命令
1 | cmake -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DMYSQL_DATADIR=/usr/local/mysql/data -DSYSCONFDIR=/etc -DWITH_MYISAM_STORAGE_ENGINE=1 -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_MEMORY_STORAGE_ENGINE=1 -DWITH_READLINE=1 -DMYSQL_UNIX_ADDR=/var/lib/mysql/mysql.sock -DMYSQL_TCP_PORT=3306 -DENABLED_LOCAL_INFILE=1 -DWITH_PARTITION_STORAGE_ENGINE=1 -DEXTRA_CHARSETS=all -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci |
使用
make && make install命令编译并安装
6.配置 MySQL
使用下面的命令查看是否有 mysql 用户及用户组
1 | cat /etc/passwd 查看用户列表 |
如果没有的话就创建
1 | groupadd mysql |
修改
/usr/local/mysql权限
1 | chown -R mysql:mysql /usr/local/mysql |
初始化配置,进入安装路径(再执行下面的指令),执行初始化配置脚本,创建系统自带的数据库和表
1 | cd /usr/local/mysql |
注:在启动 MySQL 服务时,会按照一定次序搜索
my.cnf,先在/etc目录下找,找不到则会搜索$basedir/my.cnf,在本例中就是/usr/local/mysql/my.cnf,这是新版 MySQL 的配置文件的默认位置!
注意:
在 CentOS 6.8 版操作系统的最小安装完成后,在
/etc目录下会存在一个my.cnf,需要将此文件更名为其他的名字,如:/etc/my.cnf.bak,否则,该文件会干扰源码安装的 MySQL 的正确配置,造成无法启动因此,需要修改名称,防止干扰:
1 | mv /etc/my.cnf /etc/my.cnf.bak |
7.启动 MySQL
添加服务,拷贝服务脚本到
init.d目录,并设置开机启动,在/usr/local/mysql下执行以下命令:
1 | cp support-files/mysql.server /etc/init.d/mysql |
执行下面的命令修改 root 密码,也可以将该路径增添到 PATH 路径中(即在冒号后面再添加路径和冒号
1 | cd /usr/local/mysql/bin |
重新进入以后就可以执行数据库相关操作
1 | show databases; |
备份 MySQL 的指令为:
1 | mysqldump -u用户名 -p密码 --host=主机名 数据库名 > /backup/db/xxx.sql |
五、大数据定制部分
1.Shell 简介
Shell 是一个命令行解释器,为用户提供了一个向 Linux 内核发送请求以便运行程序的界面系统级程序,用户可以用 Shell 来启动、挂起、停止甚至是编写一些程序
脚本格式要求:
1.脚本中以#!/bin/bash开头
2.脚本是个以.sh为后缀名的文件
3.脚本需要有可执行权限(一般来说)内容编写格式:
1 | #! /bin/sh |
2.Shell 执行方式
(1).赋予权限执行
给已经写好的脚本赋予所有者的执行权限
1 | chmod 744 myShell.sh |
相对路径执行
1 | ./myShell.sh |
绝对路径执行
1 | /root/shell/myShell.sh |
(2).不赋予权限执行
相对路径执行
1 | sh ./myShell.sh |
绝对路径执行
1 | sh /root/shell/myShell.sh |
3.变量
变量变量分为:系统变量(环境变量)与用户自定义变量(本地变量)
(1).系统变量
有:
$PATH、$PWD、$SHELL、$USER所有系统变量都是键值对的格式,系统变量查看命令:
1 | echo $PATH |
显示当前 Shell 中所有的变量:
set
(2).用户自定义变量
定义变量:
变量=值撤销变量:
unset 变量声明静态变量:
readonly 变量,但是静态变量不能使用撤销操作
1 | A=100 //声明普通变量 |
定义变量的规则:
可以由字母、数字和下划线组成,但是不能以数字开头等号两侧不能有空格变量名称一般习惯大写
(3).将命令的返回值赋值给变量
使用反引号,将命令写入反引号中来然后赋值给变量
1 | A=`ls -l` |
使用括号,将命令写入括号中来然后赋值给变量
1 | B=$(date) |
(4).设置环境变量
在配置文件
/etc/profile中使用如下语法来将 Shell 变量输出为环境变量
1 | TOMCAT_HOME=/opt/tomcat |
使用如下命令让修改后的配置信息立即生效
1 | source /etc/profile |
在 Shell 脚本中查询环境变量的值
1 | echo $TOMCAT_HOME |
4.位置变量参数
当执行 Shell 脚本时,如果希望获取到命令行的参数信息,就可以使用到位置参数变量
(1).语法
$n:n为数字,$0代表命令本身,$1-$9代表1-9个参数,10以上的参数需要${10}这样使用$*:这个变量代表命令行中的所有的参数,而$*把所有的参数看成一个整体$@:这个变量也代表命令行中的所有的参数,不过$@把每个参数区分对待$#:这个变量代表命令行中所有参数的个数
(2).案例
编写 positionPara.sh ,获取到命令行中的各个参数信息
1 | #!/bin/bash |
执行
./positionPara.sh 30 60命令,得到结果如下:
1 | ./positionPara.sh 30 60 |
5.预定义变量
即事先定义好的变量,可直接在 Shell 中使用
(1).语法
$$:当前进程的进程号$!:后台运行的最后一个进程的进程号$?:最后一次执行的命令的返回状态如果这个变量的值为0,则上一个命令正确执行如果这个变量的值为非0(具体有命令自己决定),则上一个命令未正确执行
(2).案例
在脚本中简单实用一下预定义变量
1 | #!/bin/bash |
执行后的结果如下:
1 | 当前的进程号=28088 |
因为这里后台运行了一个脚本,所以需要使用 ctrl+c 来暂停
6.运算符
(1).基本语法
$((运算式))或$[运算式]expr 语法,注意这里的运算符之间要有空格求和:
expr m + n求差:expr m - n求乘:expr \*求除:expr /求余:expr %
(2).案例
求(2+3)*4的值
1 | #括号法 |
求命令行里的两个参数的和
1 | #命令行中传入10和8求和 |
7.流程控制语句
(1).条件判断语法
[ 判断内容 ],在判断内容前后各有一个空格该条件判断为非空时返回 true,为空时返回 false
也可以使用
$?来验证,0为 true,1为 false
(2).常用判断条件
两个字符串的比较
[ "ok" = "ok" ]两个整数的比较:
[ 0 -lt 0 ]:小于[ 0 -le 0 ]:小于等于[ 0 -eq 0 ]:等于[ 0 -gt 0 ]:大于[ 0 -ge 0 ]:大于等于[ 0 -ne 0 ]:不等于按照文件权限进行判断:
[ -r 文件名 ]:有读的权限[ -w 文件名 ]:有写的权限[ -x 文件名 ]:有执行的权限按照文件类型进行判断:
[ -f 文件名 ]:文件存在并且是一个常规的文件[ -e 文件名 ]:文件存在[ -d 文件名 ]:文件存在并是一个目录
(3).if 判断语句
推荐语法如下:
1 | if [ 条件判断式 ] |
不推荐语法如下:
1 | if [ 条件判断式 ];then |
编写一个Shell程序,如果输入的参数大于等于60输出“ggg及格了”;小于60输出“不及格”
1 | if [ $1 -ge 60 ] |
(4).case 判断语句
语法如下:
1 | case $变量名 in |
当命令行参数是1时,输出周一;是2时,输出周二;其余输出other
1 | case $1 in |
(5).for 循环语句
语法1如下:
1 | for 变量 in "值1 值2 值3···" |
语法2如下:
1 | for ((初始值;循环控制条件;变量变化)) |
a).案例
打印命令行输入的参数
1 | #将参数作为一个整体输出 |
从1加到100的值输出显示
1 | SUM=0 |
(6).while 循环语句
语法如下:
1 | while [ 条件判断式 ] |
从命令行中输入一个数n,统计从1+··+n的值是多少
1 | SUM=0 |
8.读取控制台输入
使用 read 命令可以读取控制台的输入
read 选项 参数,选项如下:
-p:指定读取值时的提示符
-t:指定读取值时的等待的时间(秒),如果没有在指定的时间内输入,就不等待了参数:指定读取值的变量名读取控制台输入两个num值,另一个在10秒内输入
1 | read -p "请输入数字1:" NUM1 |
9.函数
shell编程和其他编程语言一样,有系统函数,也可以自定义函数
(1).系统函数
a).basename
作用:返回完整路径最后/的部分,常用于获取文件名
语法:
basename [pathname] [suffix]:basename [string] [suffix]:如果上面指定了 suffix ,那么就不会显示文件后缀名;不指定则会显示
1 | [root@hadoop1 ~]# basename /home/test.txt |
b).dirname
作用:返回完整路径最后/的前面的部分,常用于返回路径部分
语法:
dirname 文件的绝对路径从给定的包含绝对路径的文件名中去除文件名,然后返回剩下的路径
1 | [root@hadoop1 ~]# dirname /home/aaa/test.txt |
(2).自定义函数
基本语法(中括号中代表可选的):
1 | [function] 函数名[()] |
调用时直接写
函数名 值案例:
1 | #计算输入两个参数的和 |
10.综合案例之定期备份数据库
(1).需求分析
每天凌晨2:10分备份数据库 testDB 到
/data/backup/db备份开始和备份结束时能够给出相应的提示信息
备份后的文件要求以备份时间为文件名,并打包成
.tar.gz的形式,比如:2020_08_22_190501.tar.gz在备份的同时,检查是否有10天前备份的数据库文件,如果有就将其删除
(2).思路分析
第一点可以使用 crond 来实现
第二点在 shell 脚本中输出提示信息即可
第三点可以先使用一个临时文件夹来存放
.gz文件,然后最后进行打包成.tar.gz文件并删除临时文件第四点需要使用固定指令来删除10天前数据库文件
将 shell 脚本放在
/usr/sbin目录下,将备份文件放置在/data/backup/db下
(3).代码实现
shell 脚本代码如下:
1 | #!/bin/bash |
cront 代码如下:
1 | 10 2 * * * /usr/sbin/mysql_db_backup.sh |
问题解决
1.“/etc/profile” is read-only
使用sudo、使用su、修改文件权限
2.-bash: vim: command not found
使用sudo yum -y install vim*安装
3./bin/bash: q: command not found
退出时使用了错误的!q而不是q!
4.-bash: wget: command not found
使用yum -y install wget安装
5.gzip: stdin: not in gzip format
这个压缩包没有用gzip格式压缩,所以不用加z指令就可以了,即 tar -xvf 压缩包
6.安装python3提示configure: error: no acceptable C compiler found in $PATH
没有安装gcc编译器,使用yum install gcc -y安装即可